Understand the lighting model I = aT + b as a general linear transform; see what each parameter does geometrically in pixel-value space; learn why orthogonal transforms (DFT, DCT) preserve energy while general linear transforms do not.
33.2 Linear transformations
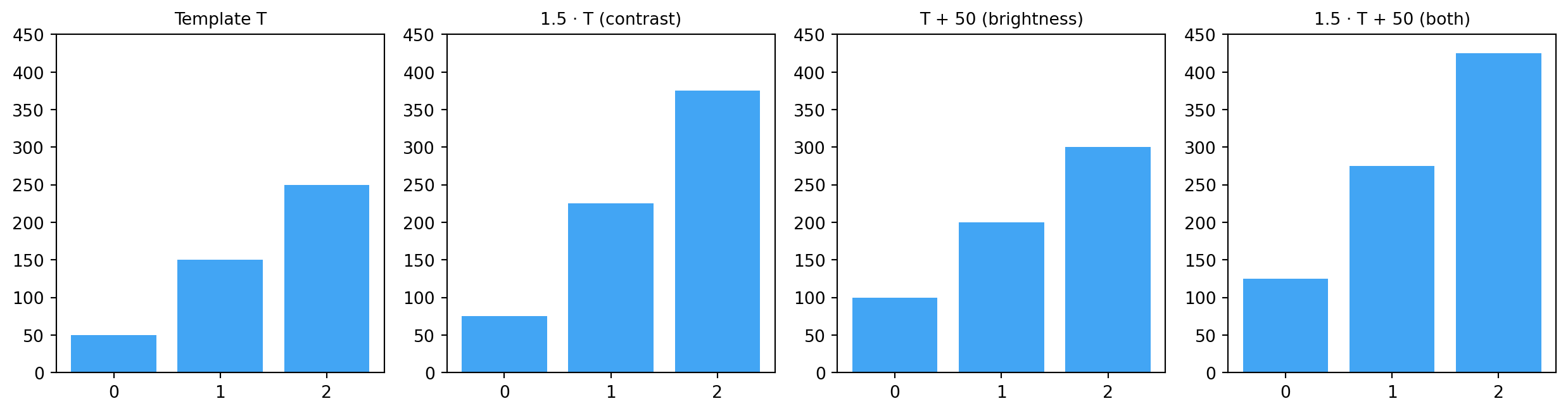
In real-world template matching, the scene patch is rarely a pixel-perfect copy of the template. Lighting changes. The relationship is modelled as a linear transform:
I \;=\; a \cdot T + b
where:
a — contrast change (stretches/compresses the pixel spread)
b — brightness offset (shifts all pixels up or down uniformly)
Geometrically:
Scaling (a) multiplies the vector by a scalar. Changes the length but not the direction. Cosine similarity handles this correctly.
Offset (b) adds b \cdot [1, 1, \ldots, 1] to the vector. Shifts the point toward the [1, 1, \ldots, 1] diagonal — changes the direction. Cosine similarity gives the wrong answer; mean subtraction is needed to undo it.
The transform distorts the signal — it stretches some directions and compresses others.
33.4 Parseval’s theorem
Transforms like the DFT (Discrete Fourier Transform) and DCT are orthogonal. When you transform a signal to the frequency domain, the total energy is the same — it is just redistributed across frequency bins instead of pixel positions. This is Parseval’s theorem:
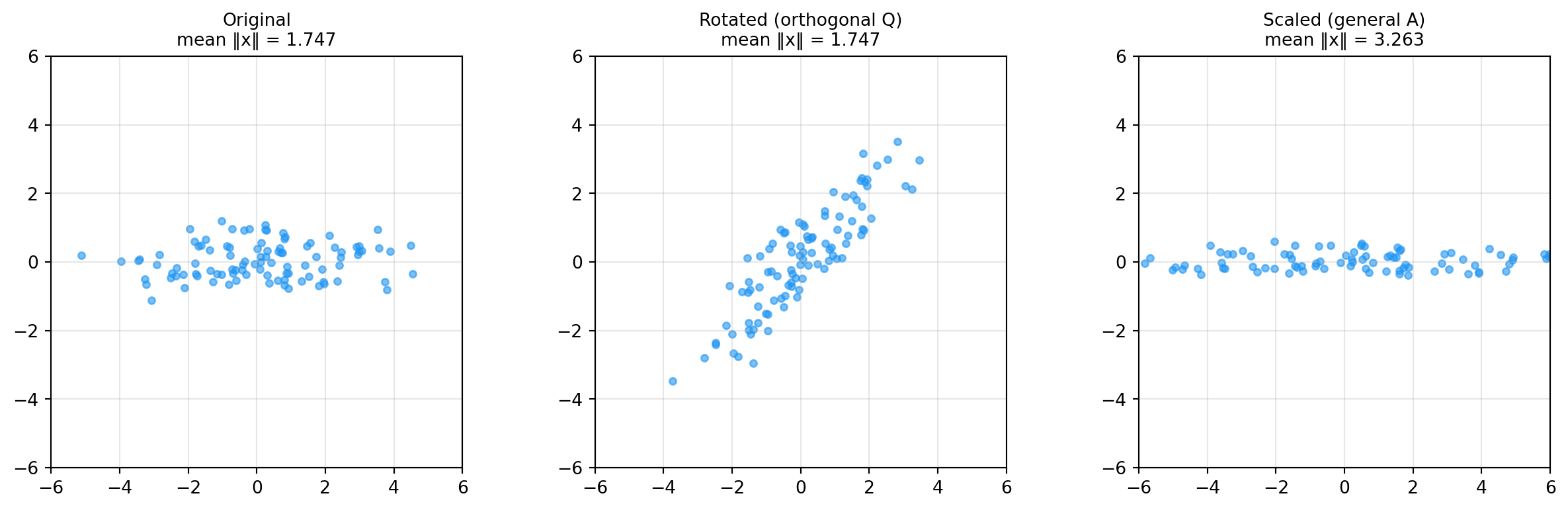
A pure rotation preserves the length of every vector. A non-orthogonal scaling does not.
The rotated cloud has the same mean length as the original — the scaled cloud doesn’t.
33.6 The hierarchy
All transforms
└── Linear transforms (T(ax + by) = aT(x) + bT(y))
├── General linear (energy may change)
│ • contrast scaling: I = 2T
│ • brightness offset: I = T + 50
│ • both: I = aT + b
│
└── Orthogonal / Unitary (energy preserved: ||Qx|| = ||x||)
• rotation matrices
• DFT, DCT
• Hadamard transform
Linearity is necessary but not sufficient for energy preservation. Orthogonality is the additional property that guarantees it.
33.7 Why this matters in ML
PCA — eigenvectors of the covariance matrix form an orthogonal basis. Projecting onto top components compresses energy into a few numbers.
Wavelets / DCT-based codecs — JPEG works because the DCT concentrates the energy of natural patches in the low-frequency bins; quantising the rest is nearly lossless.
Self-attention in transformers uses dot products and softmax-normalised similarities — the same machinery in higher dimensions.
Whitening — the data is rotated so its features are decorrelated, then scaled to unit variance. Many neural nets implicitly learn similar transforms in their early layers.
33.8 Exercises
Construct a 3 \times 3 rotation matrix. Verify Q^\top Q = I.
Generate a random vector and rotate it 100 times by 5°. Plot the evolving point. Confirm length is preserved.
Apply the DCT to a 1D signal. Plot original and reconstructed signal after zeroing the top half of frequency bins. Quantify energy lost.
The lighting model I = aT + b has two free parameters. Find a matrix A and a vector \vec c such that I = A T + \vec c is linear (in the affine sense) and equivalent.
33.9 Glossary
linear transform — a function that satisfies T(a\vec x + b\vec y)
= aT(\vec x) + bT(\vec y).
orthogonal matrix — square matrix Q with Q^\top Q = I; columns are orthonormal.
unitary matrix — complex generalisation of orthogonal; Q^* Q = I.
Parseval’s theorem — energy in time domain = energy in frequency domain (for orthogonal transforms).
DFT / DCT — orthogonal transforms to the frequency domain.
energy preservation — \|Q\vec x\| = \|\vec x\| for orthogonal Q.
affine transform — linear plus translation; I = aT + b.