“First babies are born 13 hours later. But could that just be random noise?”
We have a difference. We want to know: is this difference real, or is it the kind of thing that happens by chance even when there is no true effect?
This is hypothesis testing.
23.2 The logic
We assume, for the sake of argument, that there is no real effect — that first babies and other babies have the same pregnancy length distribution. This assumption is the null hypothesis (H_0).
If H_0 is true, we can simulate what differences we’d expect by chance. If our observed difference is unlikely under H_0, we reject H_0.
The key question: under the null hypothesis, how often would we see a difference at least as large as the one we actually observed?
That probability is the p-value.
23.3 Classical hypothesis testing — the historical setup
The classical approach (Fisher, Neyman–Pearson):
Assume H_0
Compute a test statistic (e.g., difference in means)
Compute the p-value
If p < 0.05 (an arbitrary threshold), “reject H_0”
WarningProblems with the classical setup
The 0.05 threshold is arbitrary (Fisher himself said so).
p < 0.05 does not mean the effect is large or important (Chapter 2 showed Cohen’s d = 0.029).
p > 0.05 does not mean the null is true — only that we don’t have enough evidence to reject it.
Multiple comparisons: test 20 things at p = 0.05, one will be “significant” by chance.
23.4 The permutation test — build intuition first
The cleanest way to understand hypothesis testing is by simulation.
If there is no real difference between first and other babies, then which baby is “first” is arbitrary — just a label. We could shuffle the labels and the difference in means should be about the same.
Algorithm:
Pool all observations into one group
Randomly split into two groups of the original sizes
Compute the difference in means
Repeat 2 000 times
Count how often the simulated difference is at least as extreme as the observed one
That count divided by 2 000 is the permutation p-value.
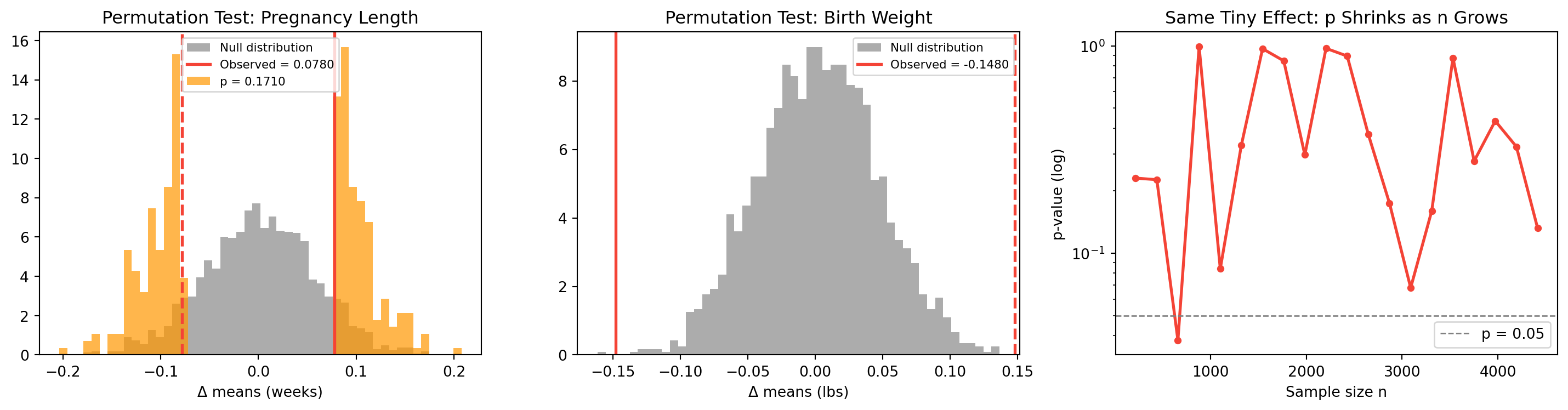
Pregnancy length:
Observed Δ mean : +0.0780 weeks p = 0.1710
Observed Δ median : +0.0000 weeks p = 1.0000
Cohen's d : +0.0289
The p-value is tiny. But Chapter 2 showed Cohen’s d ≈ 0.029 (tiny effect). How can the effect be tiny but the p-value be tiny too?
Because p-value depends on sample size. With n \approx 9000, we have enough data to detect even trivial effects. A statistically significant result is not necessarily an important result.
TipAlways report effect size and p-value
Either alone is misleading. p-value tells you whether the effect exists; effect size tells you whether it matters.
23.6 Birth weight goes the other way
obs_wgt, p_wgt, null_wgt = permutation_test(first_wgt, other_wgt, diff_means)print(f"Δ mean weight : {obs_wgt:+.4f} lbs p = {p_wgt:.4f}")print(f"Cohen's d : {cohens_d(first_wgt, other_wgt):+.4f}")
Δ mean weight : -0.1480 lbs p = 0.0005
Cohen's d : -0.0707
First babies are slightly lighter — opposite of the “born late” folklore.
23.7 p-value vs sample size
The same tiny effect can be “significant” or not depending purely on n.
print(f" {'n':>10}{'p-value':>10}{'Cohen d':>10}")for frac in [0.1, 0.25, 0.5, 0.75, 1.0]: n =int(frac *min(len(first_prg), len(other_prg))) a = np.random.choice(first_prg, size=n, replace=False) b = np.random.choice(other_prg, size=n, replace=False) _, p, _ = permutation_test(a, b, diff_means, n_permutations=1000) d = cohens_d(a, b) sig ="✓"if p <0.05else"✗"print(f" {n:>10,}{p:>10.4f}{d:>10.4f}{sig}")