The question
“Pregnancy length partly predicts birth weight. What else does?”
Chapter 10 used one predictor. Real phenomena are shaped by many variables. Multiple regression lets us use all of them simultaneously.
Multiple regression
Extend the simple model to include multiple predictors:
\hat{y} \;=\; \alpha + \beta_1 x_1 + \beta_2 x_2 + \ldots + \beta_k x_k
For birth weight we might include:
x_1 = pregnancy length (weeks)x_2 = mother’s age (years)x_3 = birth order
In matrix form: \hat{\mathbf{y}} = \mathbf{X}\boldsymbol{\beta} , with OLS solution \hat{\boldsymbol{\beta}} = (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y} .
Interpreting multiple regression coefficients
Each coefficient \hat{\beta}_j is the change in y per unit change in x_j holding all other variables constant .
This is the key advantage over simple regression: a coefficient is adjusted for the others, separating direct effects from confounds.
Nonlinear effects in regression
Chapter 7 showed mother’s age has a U-shaped relationship with birth weight. Model it with a quadratic term:
\hat{\text{weight}} \;=\;
\alpha + \beta_1 \cdot \text{age} + \beta_2 \cdot \text{age}^2
The model is still linear in the coefficients — we just created a new variable x_2 = x_1^2 . This is polynomial regression .
Fitting it with statsmodels
import sys, osimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport statsmodels.formula.api as smf0 , os.path.dirname(os.path.abspath("__file__" )) or "." )from _nsfg import load_groups, COLORS= load_groups()= live[["prglngth" , "totalwgt_lb" , "agepreg" , "birthord" ]].dropna().copy()= df[(df["totalwgt_lb" ] > 0 ) & (df["totalwgt_lb" ] < 20 )]= df[(df["prglngth" ] >= 27 ) & (df["prglngth" ] <= 44 )]= df[(df["agepreg" ] > 10 ) & (df["agepreg" ] < 50 )]"agepreg_sq" ] = df["agepreg" ] ** 2 "preterm" ] = (df["prglngth" ] < 37 ).astype(int )= smf.ols("totalwgt_lb ~ prglngth" , data= df).fit()= smf.ols("totalwgt_lb ~ prglngth + agepreg + birthord" , data= df).fit()= smf.ols("totalwgt_lb ~ prglngth + agepreg + agepreg_sq + birthord" ,= df).fit()print (f" { 'Model' :<40} { 'R²' :>6} { 'Adj R²' :>8} { 'AIC' :>10} { 'BIC' :>10} " )for name, mdl in [("prglngth only" , m1),"+ age + birthord" , m2),"+ age² + birthord" , m3)]:print (f" { name:<40} { mdl. rsquared:>6.4f} " f" { mdl. rsquared_adj:>8.4f} { mdl. aic:>10.1f} { mdl. bic:>10.1f} " )
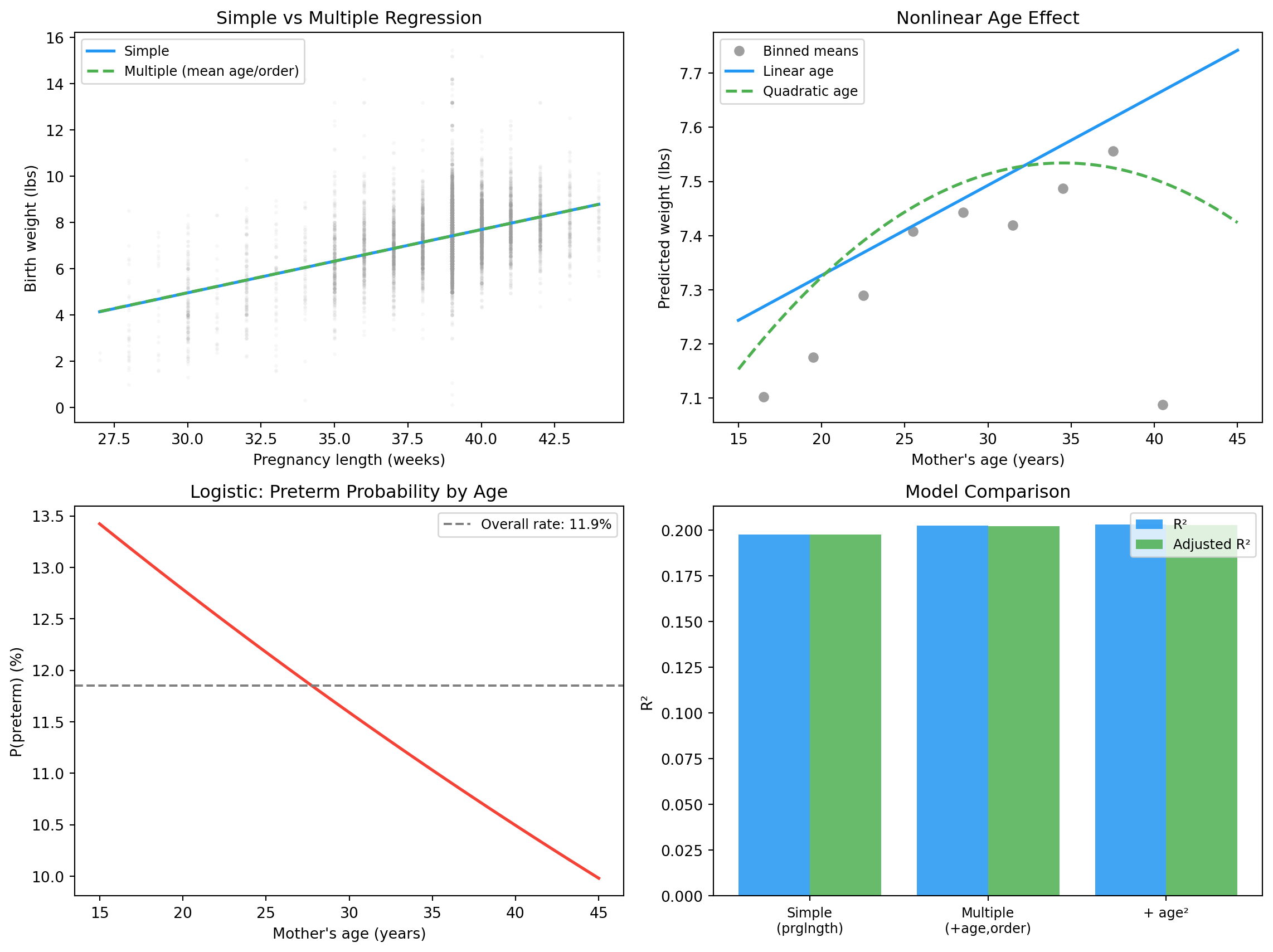
Model R² Adj R² AIC BIC
prglngth only 0.1975 0.1974 29679.9 29694.1
+ age + birthord 0.2022 0.2019 29630.7 29659.1
+ age² + birthord 0.2029 0.2025 29625.4 29660.9
Adding age and birth order improves R²; adding the quadratic age term improves it further (and AIC/BIC go down).
Coefficients in the multiple model
print (m2.summary().tables[1 ])print ()for var, label in [("prglngth" , "Pregnancy length" ),"agepreg" , "Mother's age" ),"birthord" , "Birth order" )]:= m2.params[var]= m2.pvalues[var]= "significant" if pval < 0.05 else "not significant" print (f" { label:<20} : { coef:+.4f} lbs per unit (p= { pval:.4f} , { sig} )" )
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -3.6469 0.231 -15.771 0.000 -4.100 -3.194
prglngth 0.2726 0.006 47.031 0.000 0.261 0.284
agepreg 0.0166 0.003 6.580 0.000 0.012 0.022
birthord 0.0112 0.014 0.828 0.408 -0.015 0.038
==============================================================================
Pregnancy length : +0.2726 lbs per unit (p=0.0000, significant)
Mother's age : +0.0166 lbs per unit (p=0.0000, significant)
Birth order : +0.0112 lbs per unit (p=0.4076, not significant)
Logistic regression — binary outcomes
What if the outcome is binary — preterm birth (yes/no)?
Linear regression doesn’t work (it predicts probabilities outside [0, 1] ). Logistic regression models the log-odds:
\log\frac{p}{1 - p} \;=\; \alpha + \beta_1 x_1 + \beta_2 x_2
Solving for p :
p \;=\; \frac{1}{1 + e^{-(\alpha + \beta_1 x_1 + \beta_2 x_2)}}
This is the sigmoid function — the same one used in neural networks. The coefficient transformation e^{\hat{\beta}_j} is the odds ratio for variable j .
= smf.logit("preterm ~ agepreg + birthord" , data= df).fit(disp= False )print (f"Preterm rate in data : { df['preterm' ]. mean()* 100 :.1f} %" )print ()for var in ["agepreg" , "birthord" ]:= m_logit.params[var]= np.exp(coef)= m_logit.pvalues[var]print (f" { var:<10} coef= { coef:+.4f} odds ratio= { odds:.4f} p= { pval:.4f} " )
Preterm rate in data : 11.9 %
agepreg coef=-0.0112 odds ratio=0.9889 p=0.0755
birthord coef=-0.0416 odds ratio=0.9592 p=0.2281
Each additional birth order multiplies the odds of preterm by the quoted factor.
Model comparison
How do we know if adding a predictor improves the model?
R^2 adjusted R^2 :
\bar{R}^2 \;=\; 1 - \frac{(1 - R^2)(n - 1)}{n - k - 1}
AIC / BIC penalise complexity — lower is better.F-test tests whether a group of coefficients is jointly zero.
Visualising it
= plt.subplots(2 , 2 , figsize= (12 , 9 ))# 1. Simple vs multiple line = axes[0 , 0 ]= np.linspace(27 , 44 , 100 )= m1.params["Intercept" ] + m1.params["prglngth" ] * prg_range= df["agepreg" ].mean(), df["birthord" ].mean()= (m2.params["Intercept" ]+ m2.params["prglngth" ] * prg_range+ m2.params["agepreg" ] * mean_age+ m2.params["birthord" ] * mean_bord)"prglngth" ], df["totalwgt_lb" ], alpha= 0.05 , s= 3 ,= COLORS["neutral" ])= COLORS["first" ], linewidth= 2 ,= "Simple" )= COLORS["other" ], linewidth= 2 ,= "--" , label= "Multiple (mean age/order)" )"Pregnancy length (weeks)" )"Birth weight (lbs)" )"Simple vs Multiple Regression" )= 9 )# 2. Nonlinear age effect = axes[0 , 1 ]= np.linspace(15 , 45 , 100 )= (m2.params["Intercept" ]+ m2.params["prglngth" ] * 39 + m2.params["agepreg" ] * age_range+ m2.params["birthord" ] * 1 )= (m3.params["Intercept" ]+ m3.params["prglngth" ] * 39 + m3.params["agepreg" ] * age_range+ m3.params["agepreg_sq" ] * age_range** 2 + m3.params["birthord" ] * 1 )= np.arange(15 , 48 , 3 )= [], []for lo, hi in zip (bins[:- 1 ], bins[1 :]):= (df["agepreg" ] >= lo) & (df["agepreg" ] < hi)if mask.sum () > 20 :"totalwgt_lb" ].mean())+ hi) / 2 )"o" , color= COLORS["neutral" ],= 6 , label= "Binned means" )= COLORS["first" ], linewidth= 2 , label= "Linear age" )= COLORS["other" ], linewidth= 2 ,= "--" , label= "Quadratic age" )"Mother's age (years)" )"Predicted weight (lbs)" )"Nonlinear Age Effect" )= 9 )# 3. Logistic curve = axes[1 , 0 ]= m_logit.predict(pd.DataFrame({"agepreg" : age_range,"birthord" : np.ones(len (age_range)),* 100 , color= COLORS["highlight" ], linewidth= 2 )"preterm" ].mean() * 100 , color= "grey" , linestyle= "--" ,= f"Overall rate: { df['preterm' ]. mean()* 100 :.1f} %" )"Mother's age (years)" )"P(preterm) (%)" )"Logistic: Preterm Probability by Age" )= 9 )# 4. Model comparison = axes[1 , 1 ]= ["Simple \n (prglngth)" , "Multiple \n (+age,order)" , "+ age²" ]= [m1.rsquared, m2.rsquared, m3.rsquared]= [m1.rsquared_adj, m2.rsquared_adj, m3.rsquared_adj]= np.arange(len (labels))- 0.2 , r2_vals, width= 0.4 , color= COLORS["first" ], alpha= 0.85 , label= "R²" )+ 0.2 , adj_r2, width= 0.4 , color= COLORS["other" ], alpha= 0.85 , label= "Adjusted R²" )= 9 )"R²" )"Model Comparison" )= 9 )
Exercises
Fit totalwgt_lb ~ prglngth + agepreg + birthord. Report coefficients.
Add a quadratic age term. Does adjusted R^2 improve?
Fit a logistic regression predicting preterm birth from age and birth order.
What is the odds ratio for birth order on preterm birth?
Compare AIC of the simple model (prglngth only) vs the full model.
Glossary
multiple regression — regression with more than one predictor.
coefficient — change in outcome per unit change, holding others constant.
polynomial regression — adding squared/cubic terms for nonlinear shapes.
logistic regression — models the log-odds of a binary outcome.
sigmoid — \sigma(z) = 1/(1 + e^{-z}) .
odds ratio — e^{\hat{\beta}} .
adjusted R^2 — penalised for number of predictors.
AIC / BIC — information criteria; lower = better.