“We’ve been simulating everything. When can we use formulas instead?”
All previous chapters built understanding through simulation — we shuffled, resampled, generated. But many textbooks give you formulas directly. When are those formulas valid? And when does simulation win?
28.2 Normal distributions — the special case
Many analytic results only hold when the data is normally distributed. If X \sim N(\mu, \sigma^2) and Y \sim N(\nu, \tau^2) independently, then
X + Y \;\sim\; N(\mu + \nu, \sigma^2 + \tau^2)
Sums of normals are normal. This is special — it doesn’t hold for most distributions.
28.3 Sampling distributions — the key results
If we draw samples of size n from a population with mean \mu and std \sigma:
\bar{X} \;\sim\; N\!\left(\mu, \frac{\sigma^2}{n}\right)
\quad \text{(exactly if population is normal)}
The sample mean is approximately normally distributed, regardless of the shape of the population distribution, as long as n is large enough.
“Large enough” depends on skewness:
Symmetric population → n \approx 30 usually fine
Moderately skewed → n \approx 100
Heavily skewed → n \approx 500+
Why does this matter? It is the reason normal-based formulas work in so many situations even when the data is not normal — we’re taking means of large samples, and means are approximately normal.
28.5 Watching the CLT happen
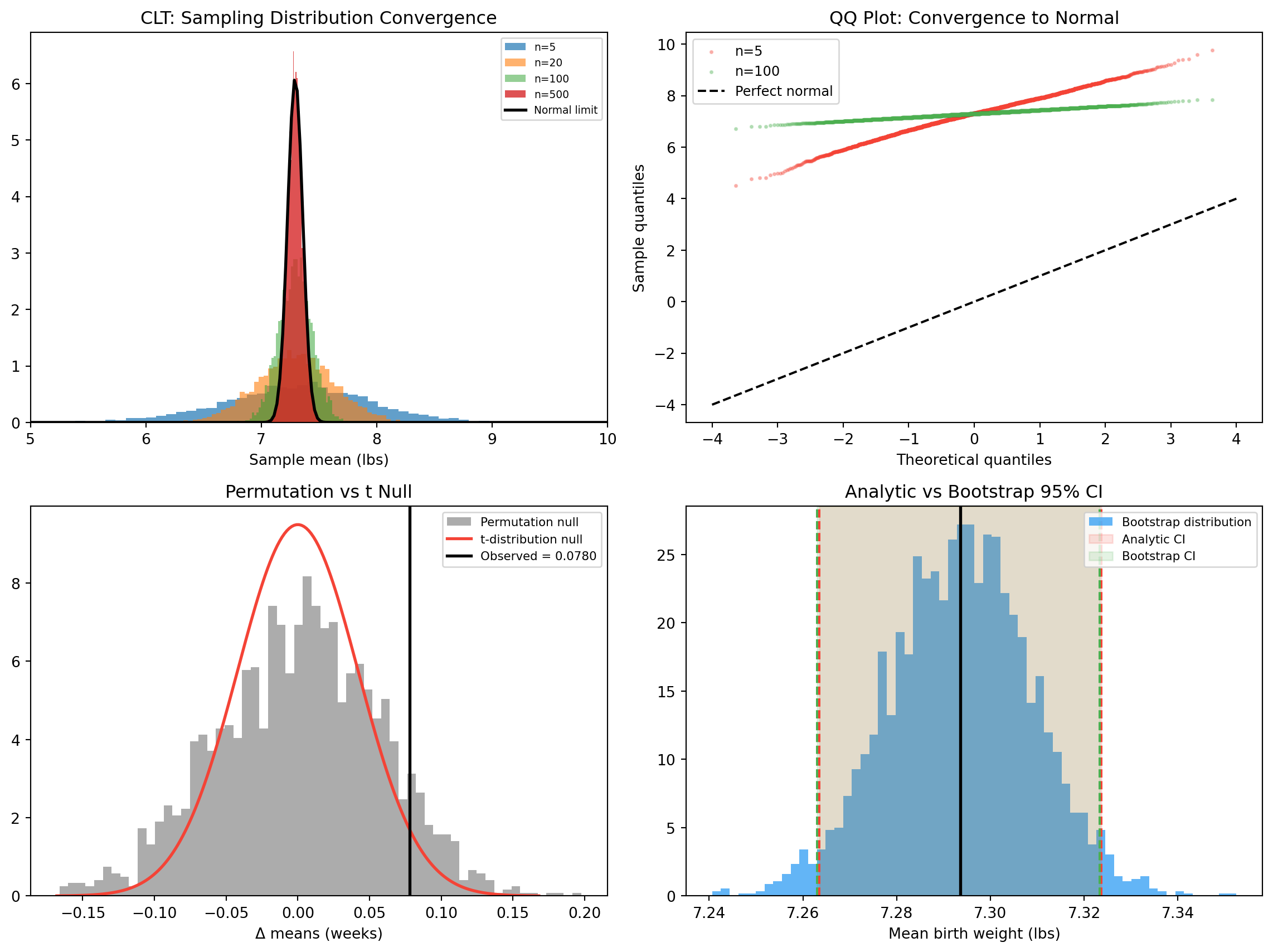
Birth weight is left-skewed (premature babies). Draw samples of increasing size and watch the sampling distribution converge to normal.
import sys, osimport numpy as npimport matplotlib.pyplot as pltfrom scipy import statssys.path.insert(0, os.path.dirname(os.path.abspath("__file__")) or".")from _nsfg import load_groups, COLORSlive, first, other = load_groups()np.random.seed(42)weights = live["totalwgt_lb"].dropna().valuesweights = weights[(weights >0) & (weights <20)]first_prg = first["prglngth"].dropna().valuesother_prg = other["prglngth"].dropna().valuessample_sizes = [5, 20, 100, 500]n_samples =5000sampling = {}print(f"Population: mean={weights.mean():.3f}, "f"std={weights.std():.3f}, skew={stats.skew(weights):.3f}")print()print(f" {'n':>6}{'mean of means':>14}{'std of means':>14} "f"{'σ/√n':>8}{'skew':>8}")for n in sample_sizes: sm = np.array([np.random.choice(weights, size=n).mean()for _ inrange(n_samples)]) sampling[n] = sm se_theory = weights.std() / np.sqrt(n)print(f" {n:>6}{sm.mean():>14.4f}{sm.std():>14.4f}"f" {se_theory:>8.4f}{stats.skew(sm):>+8.4f}")
Population: mean=7.294, std=1.463, skew=-0.254
n mean of means std of means σ/√n skew
5 7.2863 0.6513 0.6541 -0.1975
20 7.2937 0.3380 0.3270 -0.0521
100 7.2962 0.1446 0.1463 +0.0003
500 7.2936 0.0654 0.0654 +0.0049
std(means) matches the theoretical \sigma / \sqrt n to multiple decimals. The skewness goes to zero — the sampling distribution becomes symmetric and normal-shaped.
28.6 Two-sample t-test vs permutation test
For the first-baby pregnancy length question we ran a permutation test in Chapter 9. The classical alternative is the Welch’s t-test:
t \;=\; \frac{\bar{x}_1 - \bar{x}_2}
{\sqrt{s_1^2/n_1 + s_2^2/n_2}}
with Welch–Satterthwaite degrees of freedom. Under H_0, this follows a t-distribution.
CLT convergence, QQ plots, permutation null vs t-distribution null, and analytic vs bootstrap CI.
28.10 When to use which
Use simulation (permutation, bootstrap) when:
The data is heavily skewed or has outliers (CLT hasn’t kicked in yet)
The test statistic is not the mean (e.g., median, max, ratio)
You have small samples (n < 30)
The analytic formula requires assumptions you can’t verify
Use analytic methods when:
n is large and data is not extremely skewed
You need speed (simulation is 1000× slower)
You want closed-form confidence intervals
You need to communicate to an audience that expects p-values and t-statistics
28.11 Course summary
Across 14 chapters we’ve used the same NSFG dataset to build the core of statistics from scratch:
Chapters 1–2: real data, histograms, effect sizes
Chapters 3–6: PMF, CDF, modelling, PDF
Chapter 7: relationships and correlation
Chapters 8–9: estimation and hypothesis testing — by simulation
Chapters 10–11: regression, multiple and logistic
Chapters 12–13: time series and survival
Chapter 14: when formulas replace simulation
The simulation-first arc is deliberate. Once you have built a permutation test or a bootstrap from scratch, the formulas in this chapter feel like shortcuts — special cases of the simulation that work when n is large. That’s the right mental model.
28.12 Exercises
Simulate the CLT: draw samples of size n = 5, 20, 100, 500 from birth weight. Plot sampling distributions of the mean.
Run a two-sample t-test for pregnancy length. Compare to the permutation test p-value.
Compute the analytic 95 % CI for mean birth weight. Compare to the bootstrap CI.
Test the correlation between age and birth weight analytically. Same result as the permutation test?
For which NSFG variable does the sampling distribution of the mean converge slowest to normal? Why?
28.13 Glossary
CLT — sample mean is approximately normal for large n.
t-distribution — sampling distribution of the mean when \sigma is unknown; → normal as n \to \infty.
t-test — hypothesis test based on the t-statistic.
Welch’s approximation — degrees of freedom for two-sample t-test without equal-variance assumption.
chi-squared distribution — distribution of \sum (O - E)^2/E under H_0 for categorical data.
analytic method — formula-based result derived from probability theory.
normal approximation — using a normal to approximate the sampling distribution when CLT applies.
convergence in distribution — a sequence of distributions approaching a limit distribution.