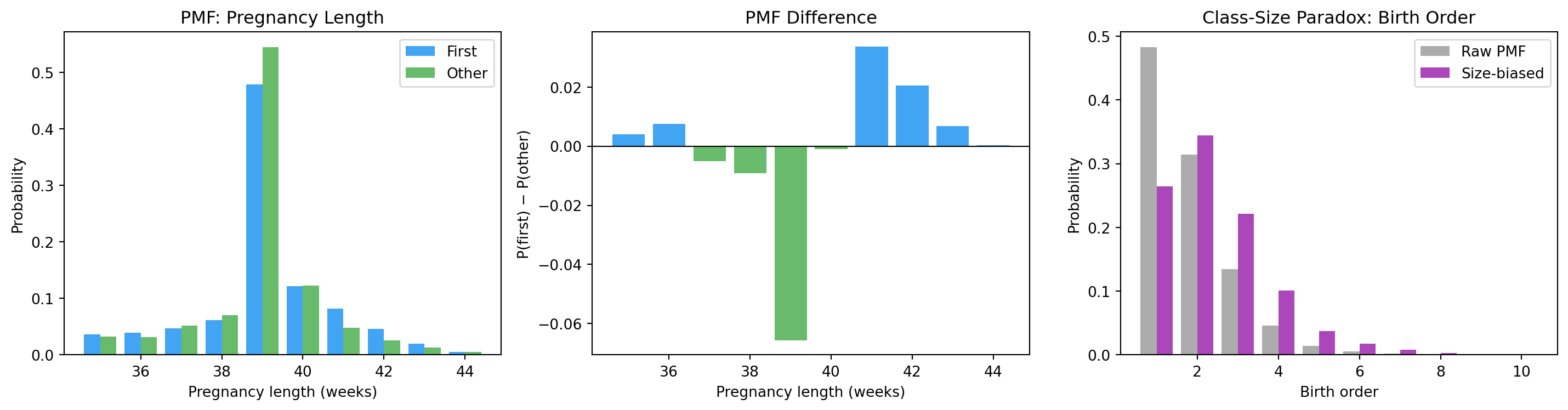
Other babies are slightly more likely to be born at exactly 39 weeks. First babies have a longer right tail. The mean difference is real, but it’s driven by the tail — not a uniform shift of the whole distribution.
17.5 Plotting PMFs
Unlike a histogram (bars touching, continuous), a PMF for discrete data is plotted as separated bars or stems — because the gaps between integer values are real: no pregnancy is 38.7 weeks long.
17.6 The class size paradox
This is one of the most elegant examples in statistics — a case where the same data gives different answers depending on who you ask.
A college has departments of varying sizes:
Department
Size
# Departments
Small
10
8
Medium
100
2
From the department’s perspective: average class size = (8 × 10 + 2 × 100) / 10 = 28 students.
From the student’s perspective: most students are in large classes; a student picked at random is more likely to be in a 100-person class. average = (80 × 10 + 200 × 100) / 280 ≈ 79 students.
Same college. Same data. Completely different averages. Why?
Because the probability of being in a large class is proportional to the class size itself. The PMF is biased by the very thing we’re measuring.
Formally, if P(X = x) is the unbiased PMF, the size-biased one is:
P(X^* = x) \;=\; \frac{x \cdot P(X = x)}{E[X]}
This is the size-biased distribution, also called the inspection paradox.
# Simulate the college from abovenp.random.seed(42)departments = [10] *8+ [100] *2dept_mean = np.mean(departments)all_students = []for size in departments: all_students.extend([size] * size)student_mean = np.mean(all_students)print(f"Departments view : {dept_mean:.1f} students")print(f"Students' view : {student_mean:.1f} students "f"({student_mean / dept_mean:.1f}x larger)")
Departments view : 28.0 students
Students' view : 74.3 students (2.7x larger)
The same paradox applies to NSFG family size: if you ask mothers how many children they have, you oversample mothers with many children (because large families contribute more respondents).
def size_biased(pmf: Pmf) -> Pmf: biased = {v: p * v for v, p in pmf.d.items()} total =sum(biased.values()) result = Pmf.__new__(Pmf) result.d = {v: c / total for v, c in biased.items()}return resultbirthord_pmf_raw = Pmf(live["birthord"].dropna().values)birthord_pmf_biased = size_biased(birthord_pmf_raw)print(f"Mean birth order (raw PMF) : {birthord_pmf_raw.mean():.3f}")print(f"Mean birth order (size-biased) : {birthord_pmf_biased.mean():.3f}")print("A random child 'experiences' a larger family than the average mother reports.")
Mean birth order (raw PMF) : 1.826
Mean birth order (size-biased) : 2.418
A random child 'experiences' a larger family than the average mother reports.
17.7 Visualising it
fig, axes = plt.subplots(1, 3, figsize=(15, 4))# 1. PMF comparisonax = axes[0]weeks =list(range(35, 45))first_p = [first_pmf.prob(w) for w in weeks]other_p = [other_pmf.prob(w) for w in weeks]x = np.array(weeks)ax.bar(x -0.2, first_p, width=0.4, color=COLORS["first"], alpha=0.85, label="First")ax.bar(x +0.2, other_p, width=0.4, color=COLORS["other"], alpha=0.85, label="Other")ax.set_xlabel("Pregnancy length (weeks)")ax.set_ylabel("Probability")ax.set_title("PMF: Pregnancy Length")ax.legend()# 2. PMF differenceax = axes[1]diffs = [first_pmf.prob(w) - other_pmf.prob(w) for w in weeks]diff_colors = [COLORS["first"] if d >0else COLORS["other"] for d in diffs]ax.bar(weeks, diffs, color=diff_colors, alpha=0.85)ax.axhline(0, color="black", linewidth=0.8)ax.set_xlabel("Pregnancy length (weeks)")ax.set_ylabel("P(first) − P(other)")ax.set_title("PMF Difference")# 3. Class-size paradox on NSFG birth orderax = axes[2]values =sorted(birthord_pmf_raw.d.keys())raw = [birthord_pmf_raw.prob(v) for v in values]biased = [birthord_pmf_biased.prob(v) for v in values]xb = np.array(values)ax.bar(xb -0.2, raw, width=0.4, color=COLORS["neutral"], alpha=0.85, label="Raw PMF")ax.bar(xb +0.2, biased, width=0.4, color="#9C27B0", alpha=0.85, label="Size-biased")ax.set_xlabel("Birth order")ax.set_ylabel("Probability")ax.set_title("Class-Size Paradox: Birth Order")ax.legend()plt.tight_layout()plt.show()
PMFs side-by-side, the first–other difference, and the size-biased birth-order paradox.
17.8 Exercises
Build a PMF of prglngth for all live births. What is the most common length?
Build PMFs for first vs other babies separately. At which week do they differ most?
Implement the class size paradox using NSFG family size data.
Build a PMF of birth order. What fraction of live births are first babies?
What is the mean of the size-biased distribution of birthord? Compare to the raw mean.
17.9 Glossary
PMF — maps each value of a discrete variable to its probability.